01
Decisions built on self-report.
The resume is the candidate's account. The interview is a performance of it. Hire on those alone and you're betting a six-figure placement on one side of the story.
The only outside check on a candidate gets rushed or skipped — right as résumé fraud climbs and a single bad hire costs $17K–$240K. RepLabIQ delivers structured voice references and a written brief in 48 hours. Real signal, before the offer goes out.
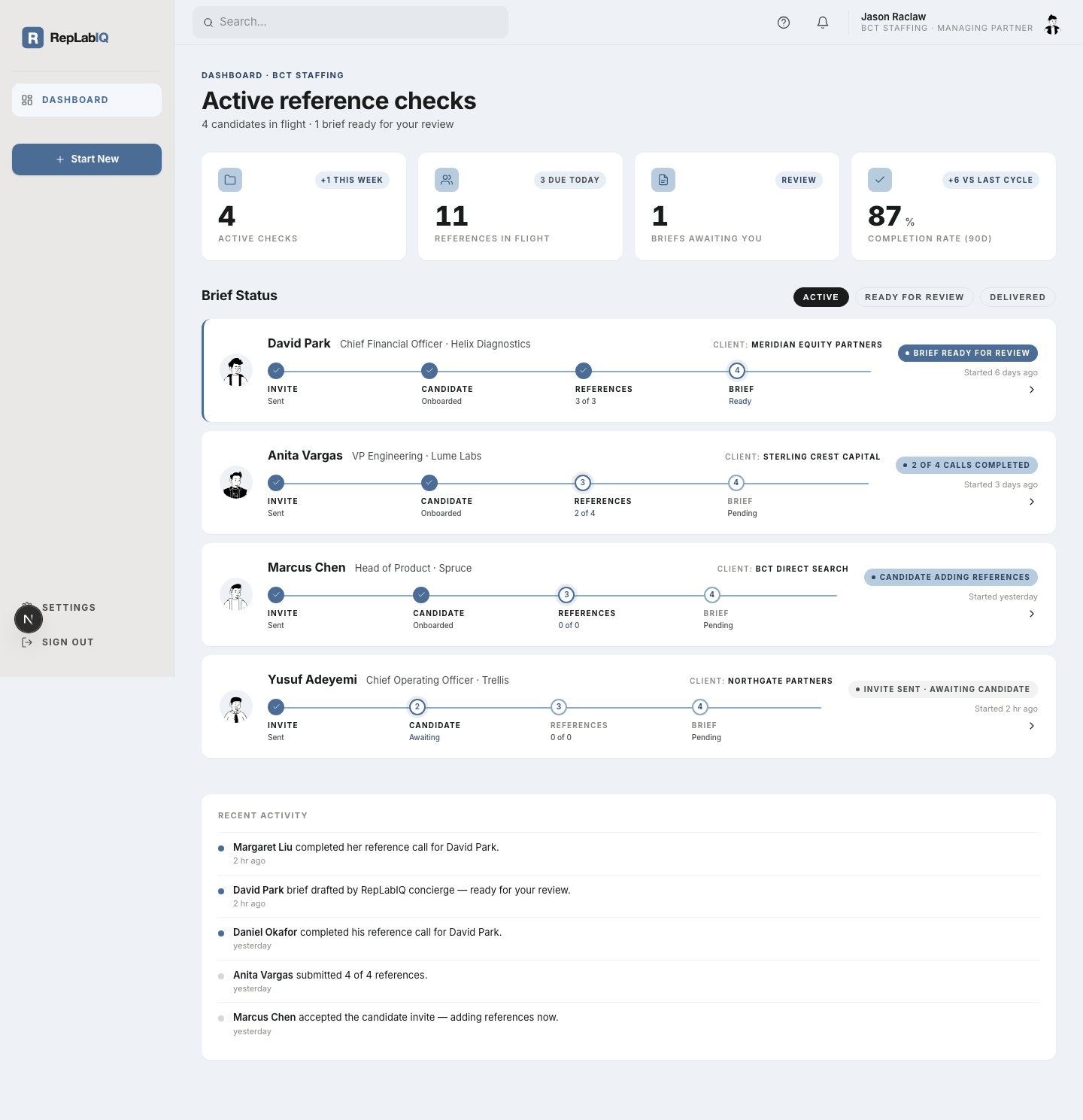
Most hiring decisions rest almost entirely on what the candidate tells you. The one step that adds independent signal — the reference check — is usually unstructured, easy to coach, and leaves nothing on the record.
The resume is the candidate's account. The interview is a performance of it. Hire on those alone and you're betting a six-figure placement on one side of the story.
More than half of candidates embellish — and AI-written resumes, coached interviews, and fabricated histories are widening the gap between what's claimed and what's real.
Without a framework, reference calls are phone tag for polite non-answers — different questions every time, nothing comparable. When confidence is needed before the offer, there's no consistent, credible artifact to point to.
For search firms it's a replacement guarantee and a clawed-back fee. For in-house teams it's lost productivity and a restart. The skipped or shallow reference check is the cheapest mistake to make and the most expensive to absorb.
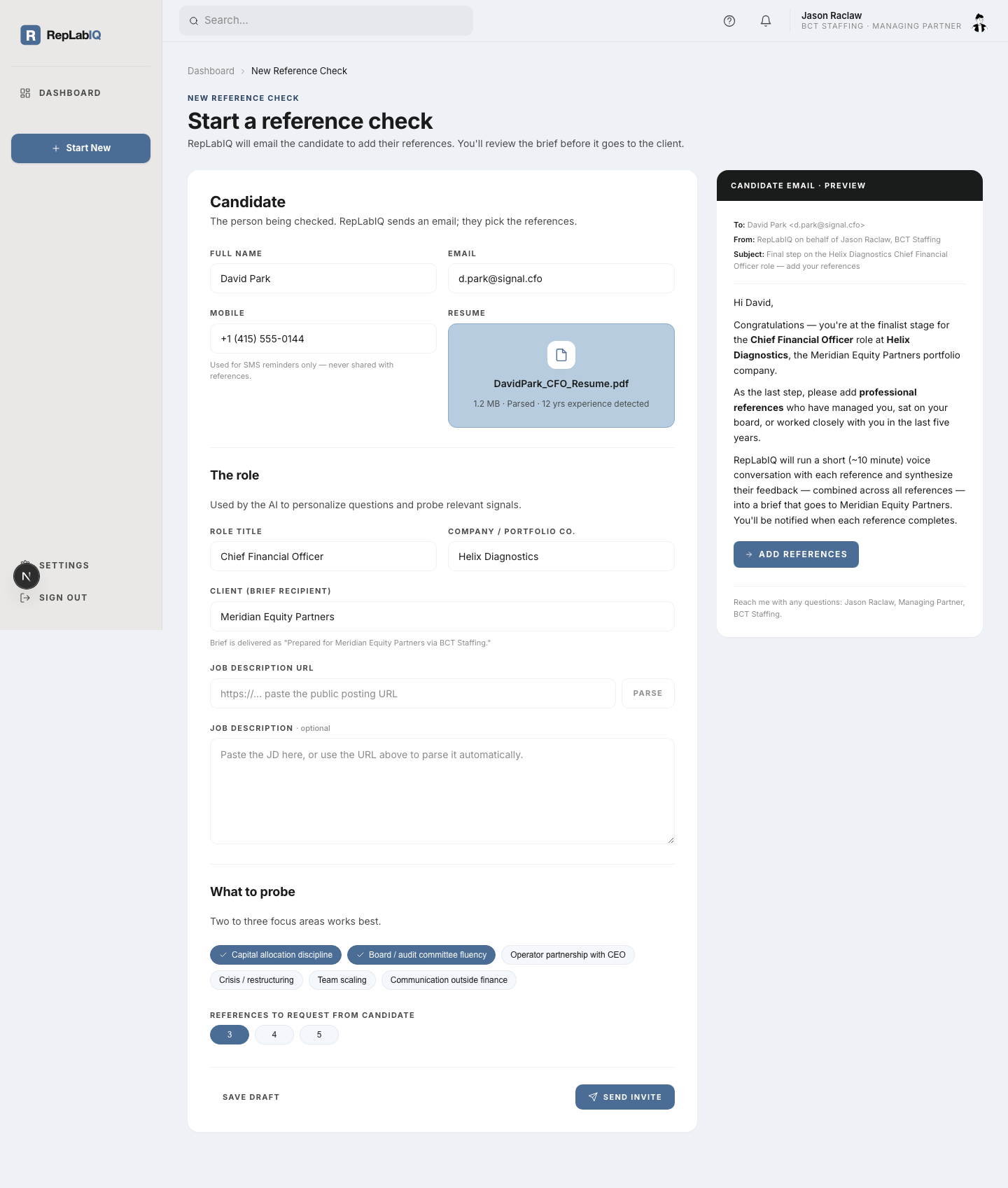
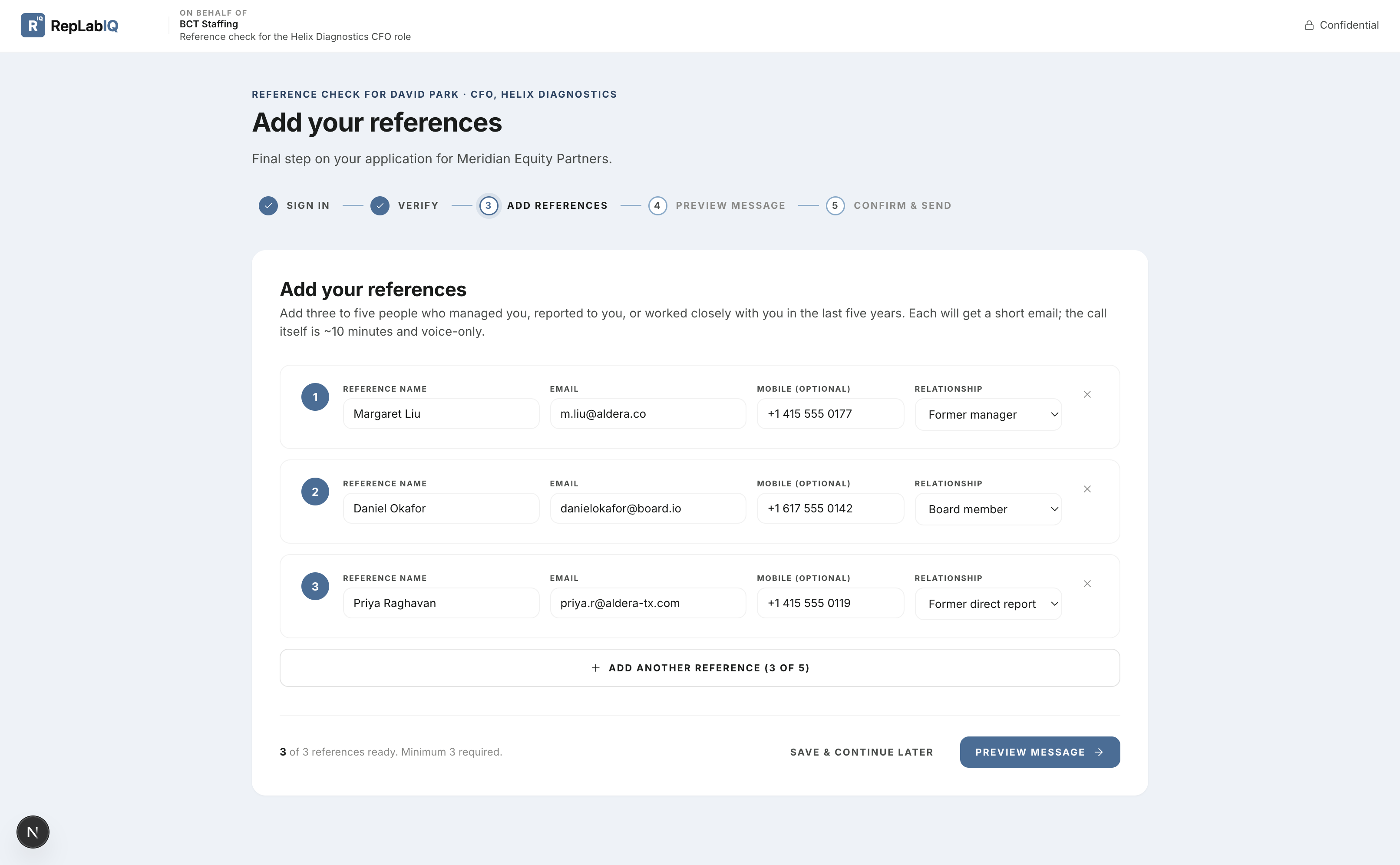
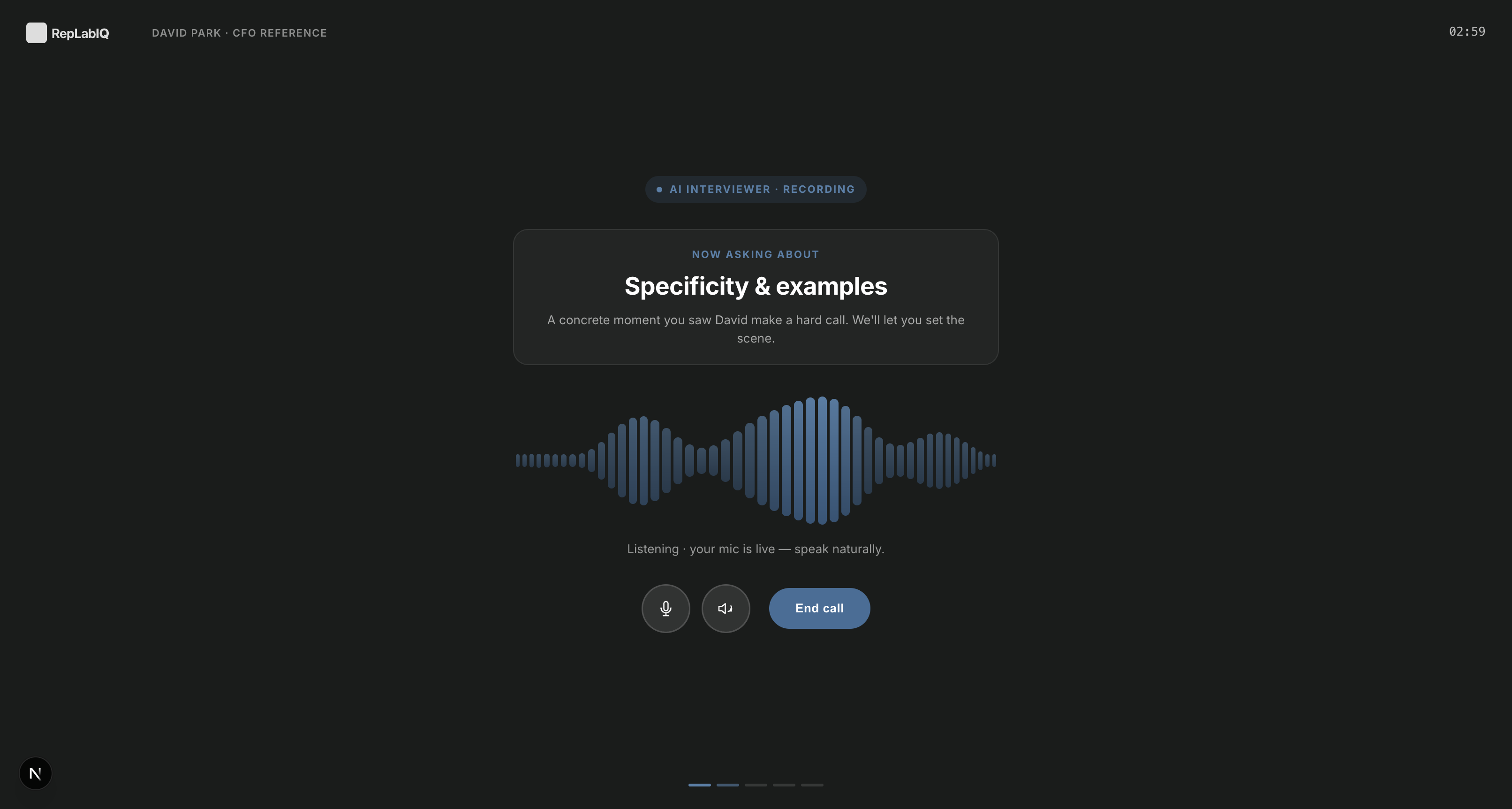
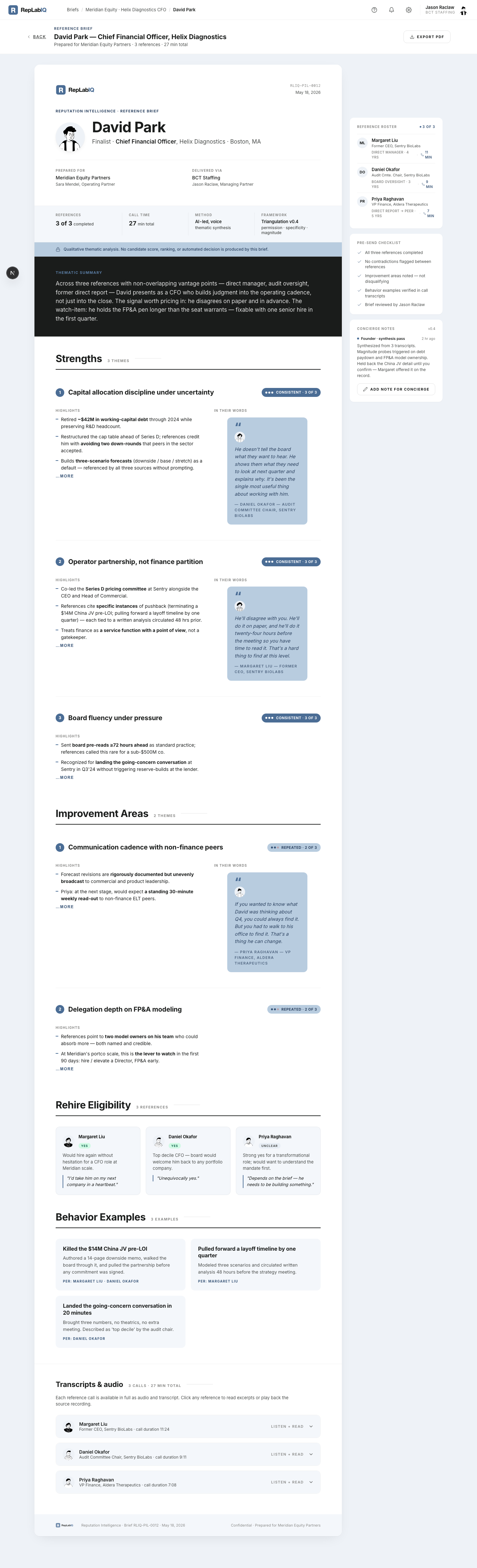
A redacted sample. Names, firms, and specifics are anonymized; the structure is exactly what you receive for every candidate.
Across three references with non-overlapping vantage points — direct manager, board oversight, former direct report — the candidate presents as a CFO who builds judgment into the operating cadence, not just the close. The signal worth pricing in: disagrees on paper and in advance. The watch-item: holds the FP&A pen longer than the seat warrants — fixable with one senior hire in the first quarter.
"He doesn't tell the board what they want to hear. He shows them what they need to look at next quarter and explains why."
— Daniel Okafor — Audit Committee Chair
"He'll disagree with you. He'll do it on paper, and he'll do it twenty-four hours before the meeting so you have time to read it."
— Margaret Liu — Former CEO
"If you wanted to know what he was thinking about Q4, you could always find it. But you had to walk to his office to find it."
— Priya Raghavan — VP Finance, prior company
Would hire again without hesitation for a CFO role at this scale.
"I'd take this candidate on my next company in a heartbeat."
Top-decile CFO — board would welcome back to any portfolio company.
"Unequivocally yes."
Strong yes for a transformational role; would want to understand the mandate first.
"Depends on the brief — needs to be building something."
Structured, behavioral reference protocols materially improve predictive validity over unstructured calls (Schmidt & Hunter, 1998; Sackett et al., 2022). Most reference processes don't do this. Ours does.
Every call follows a standardized, psychology-backed protocol grounded in behavioral interviewing — our proprietary question set, calibrated to the role and candidate and built to surface evidence rather than opinions. We don't ask 'what are their strengths and weaknesses.'
We don't score candidates. We surface qualitative patterns — themes, contradictions, signal density — using methodology traceable to structured-interview research. Surfacing rather than scoring is also what keeps RepLabIQ outside automated employment decision tool regulation.
Designed for roles where a bad hire is expensive — whether that's a search firm absorbing a replacement guarantee or an in-house team restarting a critical hire. Not for high-volume req-filling.
References are mandated but scheduling is friction and fraud is climbing. RepLabIQ runs checks asynchronously and delivers a brief in 48 hours — so the reference informs the decision instead of following it.
Whether you're a hiring manager running occasional checks or a search firm closing 30 placements a month — there's a plan that fits. Your first candidate is always on us.
* Subscriptions are billed monthly on a 12-month agreement. Pay the annual term in full, up front, and two months are free.
** Each candidate includes up to 3 references.
Tell us a little about your team. We'll run one reference free on a live candidate and show you exactly what the RepLabIQ Brief looks like on a role that matters to you.
A voice-AI interviewer trained on our standardized, behavioral framework. Calls are 5–10 minutes, voice-only, and follow a research-grounded protocol. The synthesis and brief are human-reviewed before delivery.
Yes. Every call opens with a disclosure that the interviewer is an AI agent operating on behalf of the recruiter, and that the call is being recorded. References can decline at any time.
Yes. We handle TCPA notice, two-party consent in states that require it (CA, MA, FL, and others), and disclosure language for AI-conducted calls. The compliance layer is built in.
For most agencies, the real comparison isn't AI vs. expert human — it's a standardized AI-led call vs. a 15-minute human call running on autopilot. The behavioral framework is the differentiator. The AI is the delivery mechanism.
No — and that's deliberate. We produce qualitative themes, supporting quotes, improvement areas, and recommended follow-ups. Because we never assign a score or ranking, the brief sits outside automated employment decision tool rules — an increasingly important distinction as regulators sharpen their scrutiny of algorithmic candidate scoring.
Starting at $300 per candidate with no commitment, or flat monthly plans from $900 for teams running regular checks. Your first candidate is always free. See full pricing above.
The brief is shared only with the hiring team — the people involved in the decision. Candidates never see it, are never told what was said, and the content is treated as confidential hiring-process information. You control who on your team has access, and it is never surfaced to the candidate at any point in the process.
We're built for roles where a bad hire is genuinely costly — in-house TA teams, executive and professional search firms, and hiring managers running high-stakes searches. We're not the right fit for pure high-volume, req-filling operations where speed is the only variable, or for teams looking to score and rank candidates algorithmically.